数据库设计基本概念和思路
基本概念
单库
分组
分片
分组+分片
各自优缺点
单库
- 主要优点:简单。
- 主要缺点:可用性不高、并发不大、数据量不能太大。
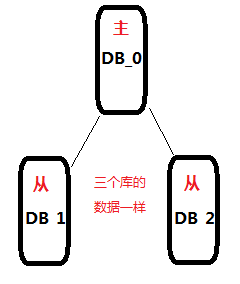
分组
- 主要优点:可用性强。
- 主要缺点:一致性差、从库越多,同步越慢,越容易不一致。
- 必要条件:中间件。用来维护主从一致性(门槛高,一般只有大公司才有)。
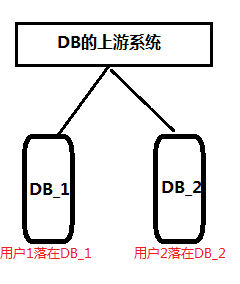
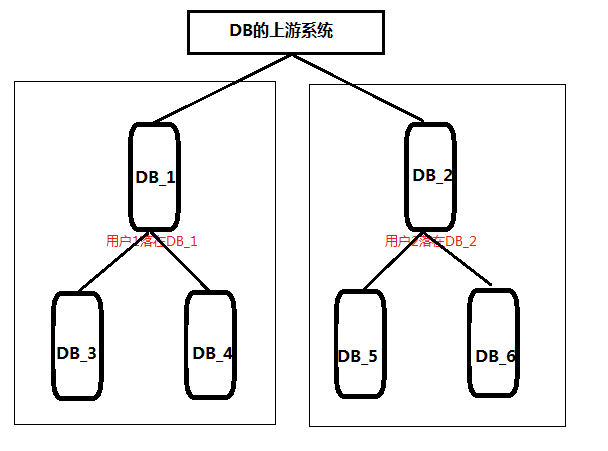
分片
- 主要优点:能存储大量数据。
- 主要缺点:主键生成麻烦、扩展性差。
- 必要条件:数据路由。
数据路由常用的三种方法:
- 范围:range
- 优点:简单、易扩展
- 缺点:各库压力不均
- 哈希:hash
- 优点:简单、数据均衡、负载均衡
- 缺点:扩展麻烦(2库扩3库需要迁移数据,2库扩4库稍简单)
- 路由服务:route-config-server
- 优点:灵活、业务与路由解耦和
- 缺点:每次访问数据库前多一次查询
设计思路
- 可用性
- 读性能
- 一致性
- 扩展性
可用性
提高可用性的思路是冗余! 如果要提高数据的可用性,可以采用分组的数据库架构。
读性能
- 读写分离
- 采用
分组的数据库架构 - 写操作使用主库,读操作使用从库,减小等锁的时间
- 采用
- 使用缓存
- 不同的库建立不同的索引
- 写库不建索引
- 线上读库建线上常用的索引
- 线下读库建线下常用的索引
一致性
- 主从不一致
- 解决方案:数据库中间件(门槛高)
- db和cache不一致
- 缓存管理:在写库时,要先更新或淘汰cache
- 超时时间:建议给每个cache都设置超时时间
扩展性
采用哈希路由时,想要平滑的扩展数据库,就只能翻倍,2库变4库,4库变8库,否则需要数据迁移。下面是平滑的把2个库扩展成4个库的步骤:
原库的数据:
- 库1的id:Mod2==0
- 库2的id:Mod2==1
增加2个新库:库3、库4
把库1数据同步到库3,库2同步到库4
修改数据路由的hash算法,以前Mod2、现在Mod4
新库的数据:
- 库1的id:Mod2==0 + Mod4==0
- 库2的id:Mod2==1 + Mod4==1
- 库3的id:Mod2==0 + Mod4==2
- 库4的id:Mod2==1 + Mod4==3
需去重的数据:
- 干掉库1中的:Mod4==2
- 干掉库2中的:Mod4==3
- 干掉库3中的:Mod4==0
- 干掉库4中的:Mod4==1
最终的数据:
- 库1的id:Mod4==0
- 库2的id:Mod4==1
- 库3的id:Mod4==2
- 库4的id:Mod4==3
